MiniMax Hailuo 02, World-Class Quality, Record-Breaking Cost Efficiency
Today, we are thrilled to introduce MiniMax Hailuo 02, our highly anticipated new video generation model.
The video showcased above was a collaborative effort by three artists over the course of 1.5 days. They utilized MiniMax Hailuo 02 to generate multiple 6-10 second video clips, which were then skillfully edited into a final video. Key Highlights of Hailuo 02: - Native 1080p - SOTA Instruction Following - Extreme Physics Mastery
Indeed, artists have discovered that for highly intricate scenarios, such as gymnastics, MiniMax Hailuo 02 is currently the only model globally capable of delivering such performance. We eagerly invite the community to explore and unlock even more creative possibilities. Our journey began late last August when we informally launched a demo webpage showcasing an early version of our video generation model. To our surprise, it attracted significant attention and acclaim from talented creators worldwide. This pivotal moment led to the development of Hailuo Video 01, our AI native video generation product, which has since empowered creators to generate over 370 million videos globally. Returning to our foundational principle of "Intelligence with Everyone," our ambition is to equip global creators to fully unleash their imagination, elevate the quality of their video content, and lower the barriers to video creation. Crucially, we strive to achieve this without imposing prohibitive costs that would limit the widespread accessibility of this technology. To this end, our team embarked on a quest to develop a more efficient video generation model architecture. This pursuit culminated in the core framework of MiniMax Hailuo 02, which we've named Noise-aware Compute Redistribution (NCR). In essence, the new architecture's central idea is as follows:
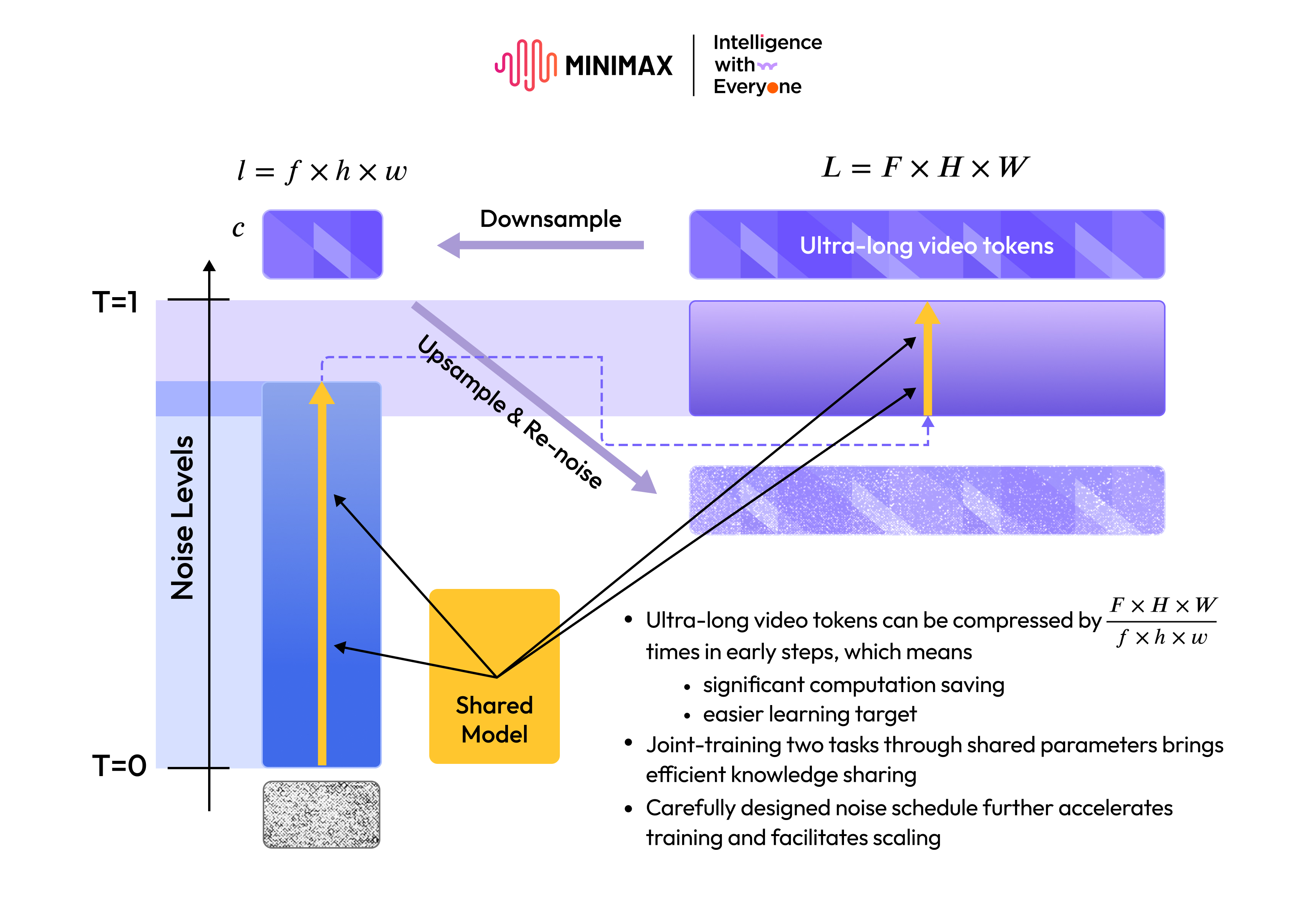
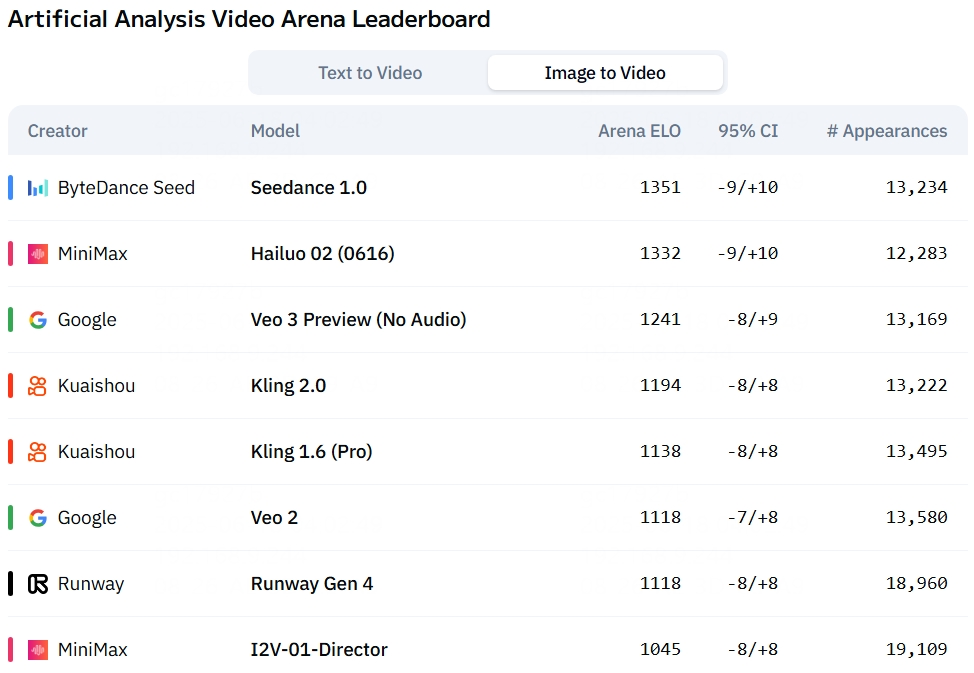
At a comparable parameter scale, the new architecture boosts our training and inference efficiency by 2.5 times. This significant gain enables us to implement a much larger parameter model—thereby enhancing its expressive capabilities—without increasing costs for creators. This approach also leaves ample room for inference optimization. We ultimately expanded the model's total parameter count to 3 times that of its predecessor. A larger parameter count and heightened training efficiency mean our model can learn from a more extensive dataset. The wealth of feedback from Hailuo 01 provided invaluable guidance for our model trainingstrategy. As a result, we expanded our training data volume by 4 times, achieving significant improvements in data quality and diversity. With this architectural innovation, combined with a threefold increase in parameters and four times the training data, our model has taken a significant leap forward, particularly in its adherence to complex instructions and its rendering of extreme physics. The new model accurately interprets and executes highly detailed prompts, delivering more precise outputs. Furthermore, the efficiency gains from the new architecture also mean we can offer native 1080p video generation at a very affordable price point. An early iteration of this model was tested by users on the Artificial Analysis Video Arena, where it secured the second position globally. Stay tuned for an upcoming new version!
These model enhancements are now fully integrated into the Hailuo Video web platform, mobile application, and our API platform. We currently offer three distinct versions: 768p-6s, 768p-10s, and 1080p-6s. True to our commitment, and thanks to the aforementioned architectural innovation, we continue to offer creators and developers the most open access and affordable pricing in the industry. A comparison of official pricing for different models is detailed below:

Through sustained technological research and development, coupled with deep collaborations with creators, developers, and artists, our mission and strategic direction have become ever clearer. MiniMax Hailuo 02 represents a new milestone, and we are poised for rapid advancements in the following areas: - Enhancing generation speed - Improving alignment, leading to higher generation success rates and improved stability - - Advancing model features beyond Text-to-Video (T2V) and Image-to-Video (I2V) And, as always, we remain steadfast in our commitment to relentlessly exploring the upper limits of what technology and art can achieve together.
Intelligence with Everyone.

