
As intelligent agents and smart devices increasingly permeate our lives in unprecedented ways, AI voice interaction is experiencing explosive growth. This surge is not just about scaling usage—it demands personalization at scale. With a rapidly growing ecosystem of devices, users, and content creators, there’s a pressing need for a unified model capable of delivering tailored voice experiences that go beyond natural and warm speech: true voice personalization must be solved.
While today’s leading text-to-speech (TTS) models are technically impressive, they often offer limited voice styles and language options. This not only narrows user choice, but also fails to reflect the cultural richness and diversity inherent in human speech.
To bridge this gap, we’ve developed a high-quality TTS system based on an AR Transformer architecture: MiniMax Speech 02. The model demonstrates strong generalization capabilities, supporting 32 languages across a wide range of accents and emotional expressions.
At the heart of MiniMax Speech 02 lies a key innovation—Intrinsic Zero-Shot Text-to-Speech with a Learnable Speaker Encoder. We designed a learnable timbre extractor that works in tandem with the AR Transformer, enabling seamless cooperation between the voice style and the content generation mechanisms.
By co-training the speaker encoder with the AR Transformer, we’ve significantly enhanced synthesis quality. This unified framework empowers the model to generate virtually unlimited combinations of language × accent × voice, greatly expanding the diversity and expressiveness of AI-generated speech.
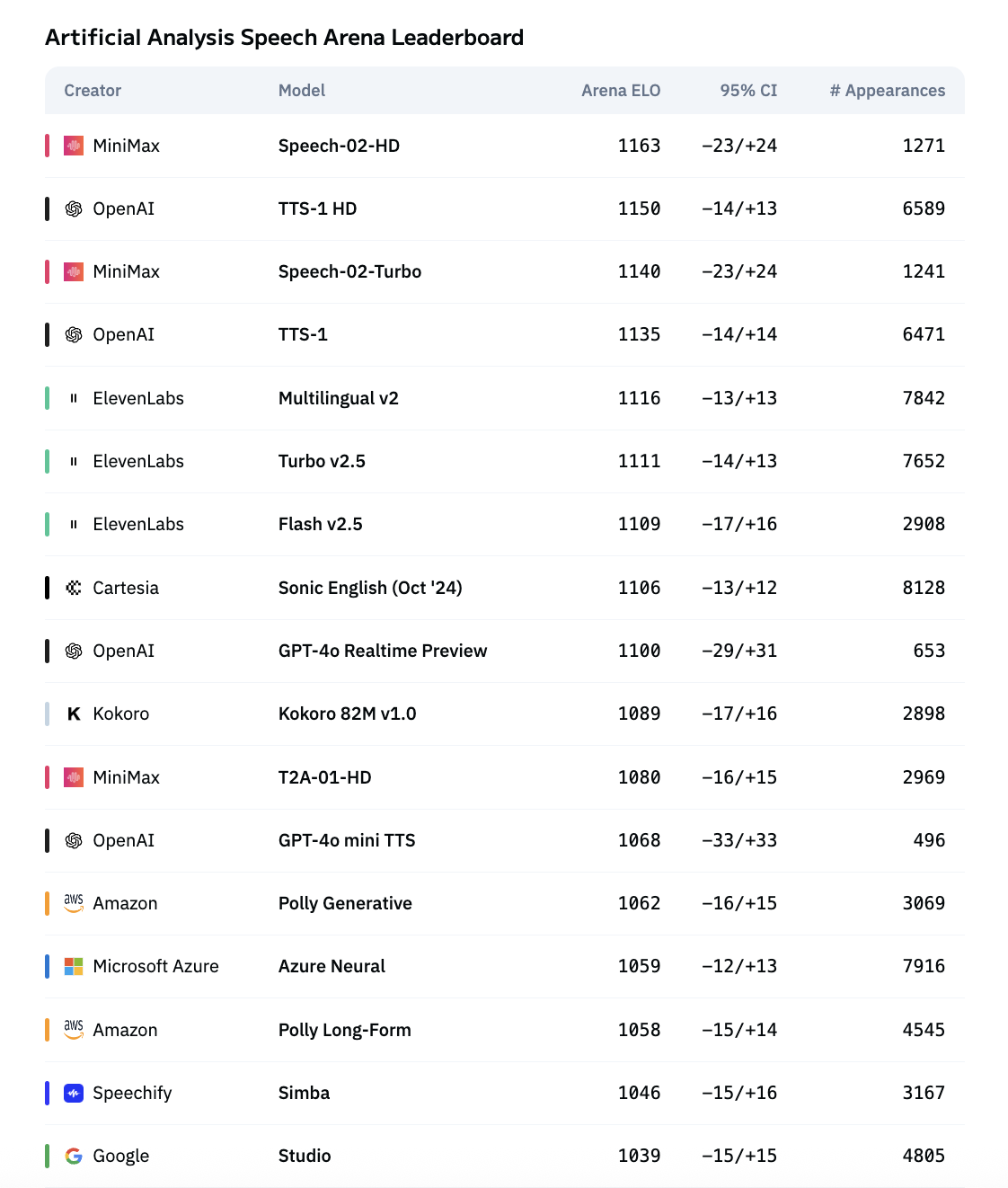
Globally Recognized: #1 on Two Benchmark Leaderboards
MiniMax Speech 02 has also earned top honors on Artificial Analysis Speech Arena and Hugging Face TTS Arena—two of the most authoritative global benchmarks in speech synthesis. Listed as Speech-02-HD in both evaluations, the model outperformed industry leaders including OpenAI and ElevenLabs to claim #1 on both charts.
Beyond standard metrics, Speech Arena’s ELO ranking—based on crowdsourced user comparisons of audio samples—highlights a key strength of MiniMax Speech 02: superior user-perceived audio quality. These results affirm that our model not only leads in technical performance, but also delivers a distinctly better listening experience for users worldwide.

For more technical details, comparative experimental results, and access to our open-source multilingual test set, we invite you to read the full technical report:
https://minimax-ai.github.io/tts_tech_report/
We invite you to explore the MiniMax Audio page to experience the full capabilities of MiniMax Speech in action.
https://www.minimax.io/audio
