MiniMax-M1, the World's First Open-Source, Large-Scale, Hybrid-Attention Reasoning Model

Introducing our new model, MiniMax-M1, the world's first open-source, large-scale, hybrid-attention reasoning model. In complex, productivity-oriented scenarios, M1's capabilities are top-tier among open-source models, surpassing domestic closed-source models and approaching the leading overseas models, all while offering the industry's best cost-effectiveness.
A significant advantage of M1 is its support for an industry-leading 1 million token context window, matching the closed-source Google Gemini 2.5 Pro. This is 8 times that of DeepSeek R1 and includes an industry-leading 80,000 token reasoning output.

This is primarily due to our proprietary hybrid-attention, which features a Lightning Attention mechanism, making it remarkably efficient for computing long context inputs and deep inference. For example, when performing deep reasoning with 80,000 tokens, it requires only about 30% of the computing power of DeepSeek R1. This feature gives us a substantial computational efficiency advantage in both training and inference.
Furthermore, we have proposed a faster reinforcement learning algorithm, CISPO, which improves RL efficiency by clipping importance sampling weights rather than through traditional token updates. In AIME experiments, we found that its convergence performance is twice as fast as other RL algorithms, including ByteDance's recent DAPO, and significantly superior to the GRPO used in the early stages of DeepSeek.
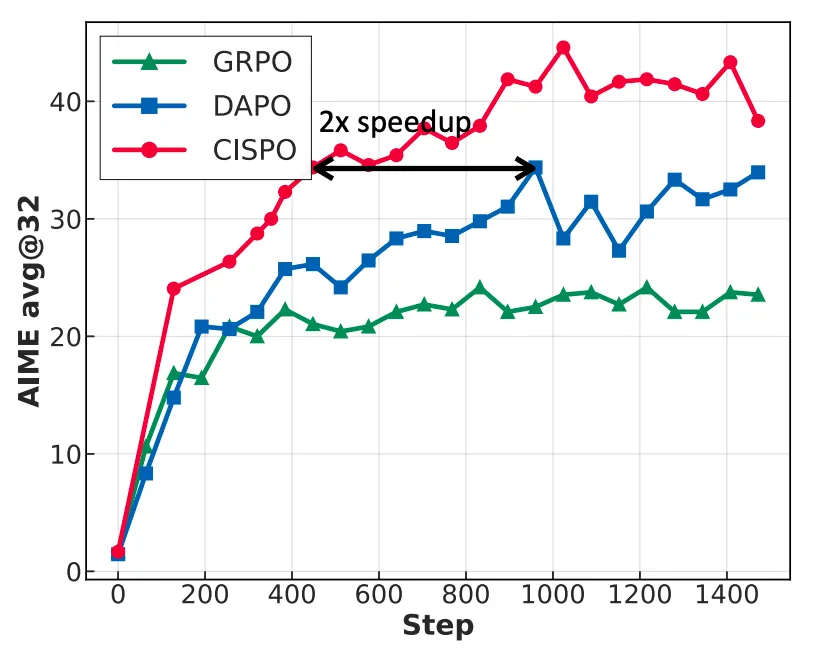
Thanks to these two technological innovations, our final reinforcement learning training process was exceptionally efficient, exceeding expectations. The entire reinforcement learning phase used only 512 H800s for three weeks, with a rental cost of just $534,700. This is an order of magnitude less than initially anticipated.
We have evaluated M1 in detail on 17 mainstream industry benchmark sets, with the specific results as follows:
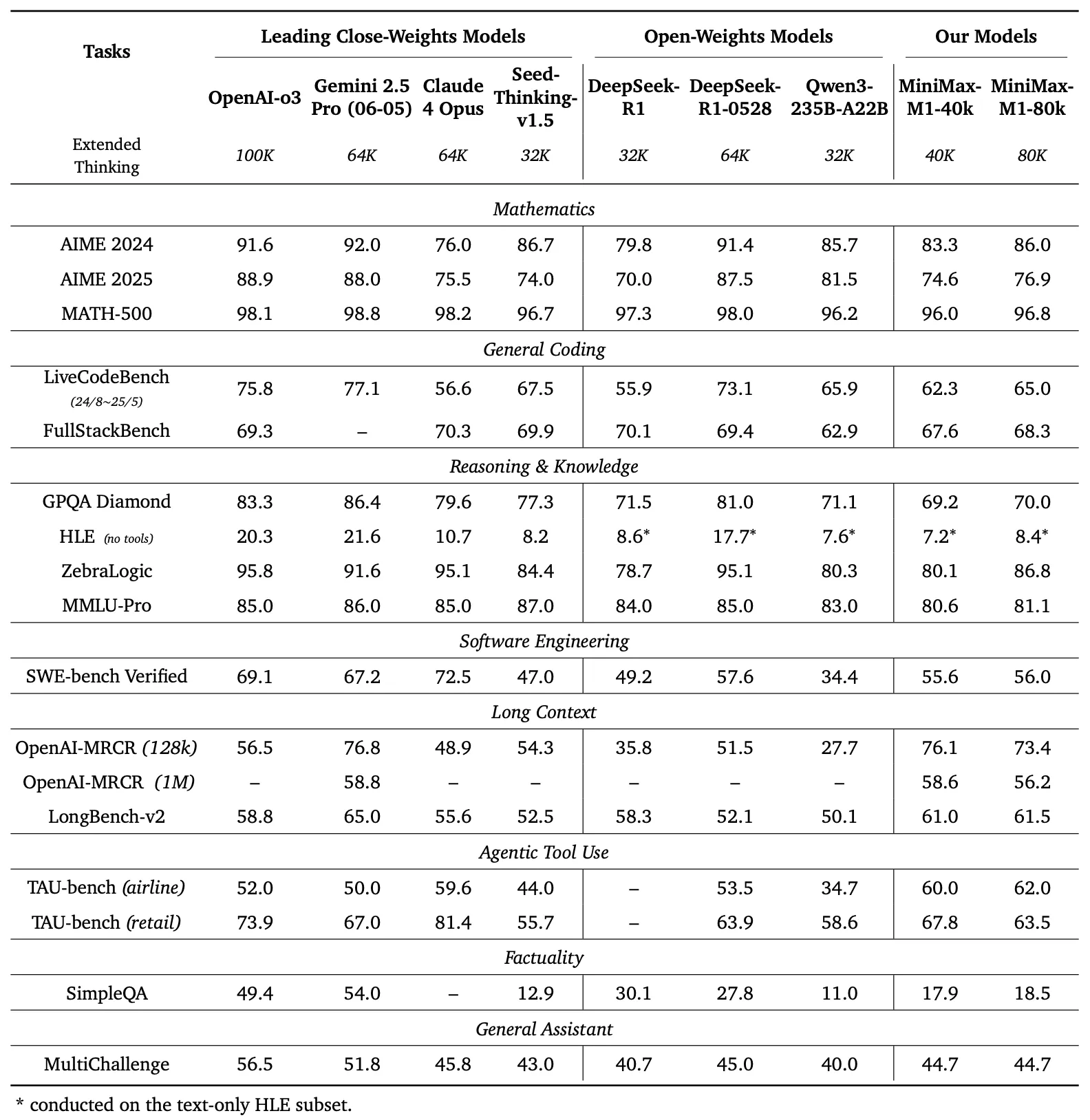
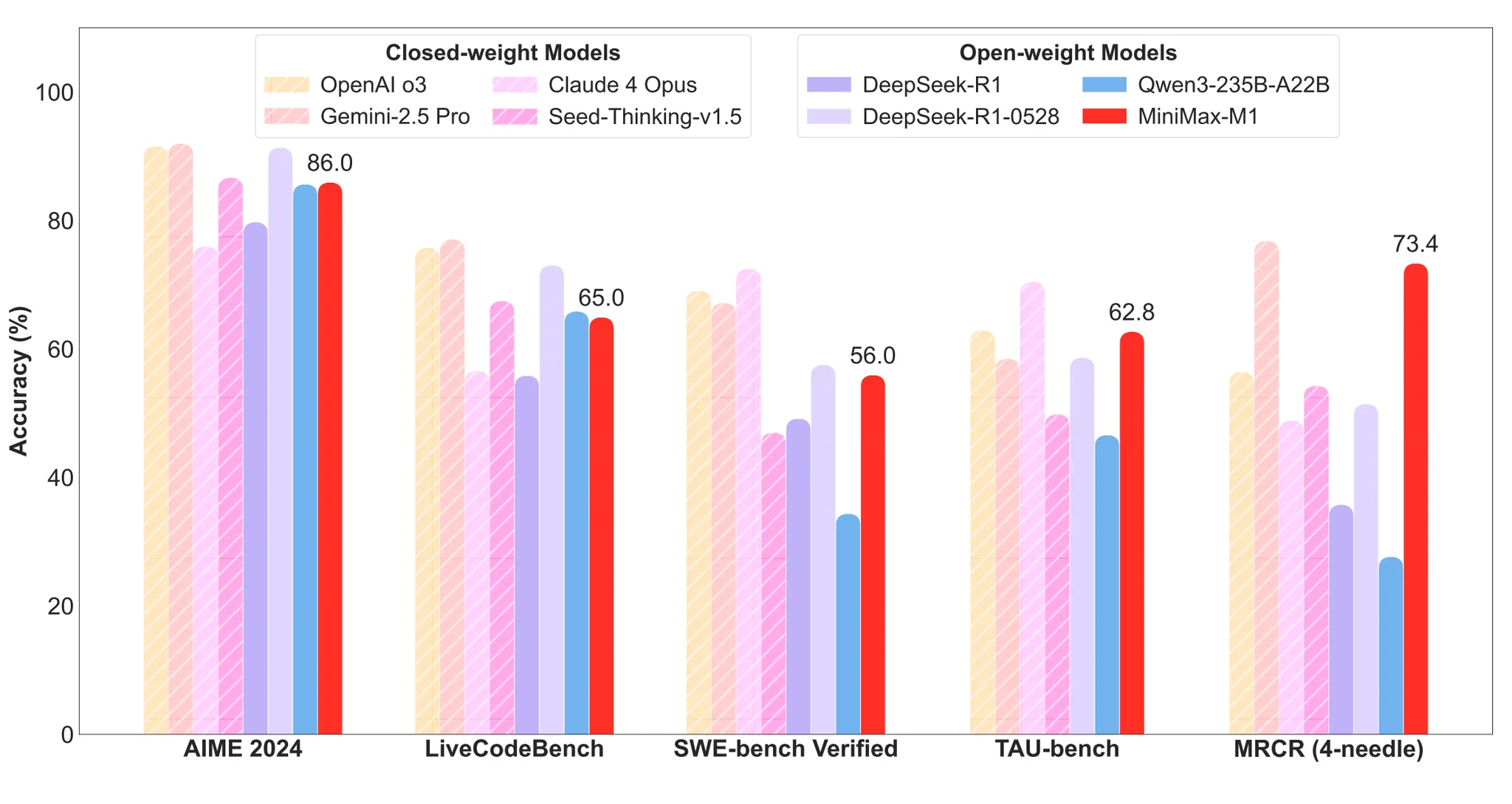
We found that our model demonstrates significant advantages in complex, productivity-oriented scenarios such as software engineering, long context, and tool use.
· MiniMax-M1-40k and MiniMax-M1-80k achieved excellent scores of 55.6% and 56.0% respectively on the SWE-bench validation benchmark. This performance is slightly below DeepSeek-R1-0528's 57.6% but significantly surpasses other open-weight models.
· Leveraging its million-token context window, the M1 series excels in long-context understanding tasks, not only outperforming all open-weight models but also surpassing OpenAI o3 and Claude 4 Opus, ranking second globally and trailing only slightly behind Gemini 2.5 Pro.
· In agent tool use scenarios (TAU-bench), MiniMax-M1-40k also leads all open-weight models and outperforms Gemini-2.5 Pro.
· It is noteworthy that MiniMax-M1-80k consistently outperforms MiniMax-M1-40k across most benchmarks, which fully validates the effectiveness of extended computational resources during testing.
Detailed technical reports and complete model weights are available on our official Hugging Face and GitHub accounts. The vLLM and Transformer open-source projects provide their own inference deployment support, and we are also collaborating with SGLang to advance deployment support.
Due to its relatively efficient use of training and inference computing power, we are offering unlimited free use on the MiniMax APP and Web, and providing APIs on our official website at the industry's lowest prices. For input lengths of 0-200k, the price is $0.4/million tokens for input and $2.2/million tokens for output. For the longest input lengths of 200k-1M, the price is $1.3/million tokens for input and $2.2/million tokens for output. The first pricing tier is more cost-effective than DeepSeek-R1, and the second tier is not supported by the DeepSeek model.
In addition to M1, we have more updates to share with you over the next four consecutive workdays. Stay tuned.
Intelligence with Everyone.
