MiniMax M3
Coding & Agentic Frontier. 1M-context MSA. Native Multimodality
The first open-weight model with three frontier capabilities.
Performance Benchmark
M3 achieves top-tier performance on coding and agentic benchmarks, with autonomous task decomposition, tool invocation, and multi-step reasoning capabilities — providing a reliable foundation for AI coding assistants and automated workflows.
Powered by the proprietary MiniMax Sparse Attention (MSA) architecture, M3 API supports up to 1M tokens context window with a guaranteed minimum of 512K tokens. The 1M context is the infrastructure for long-range Agent tasks, long-range Coding, and long-video understanding.
A natively multimodal model. The entire data pipeline was rebuilt to scale pretraining data to 100T+, with multimodal training from step zero achieving deep alignment between textual and visual semantic spaces. Multimodal is a native core capability, not a superficial add-on.
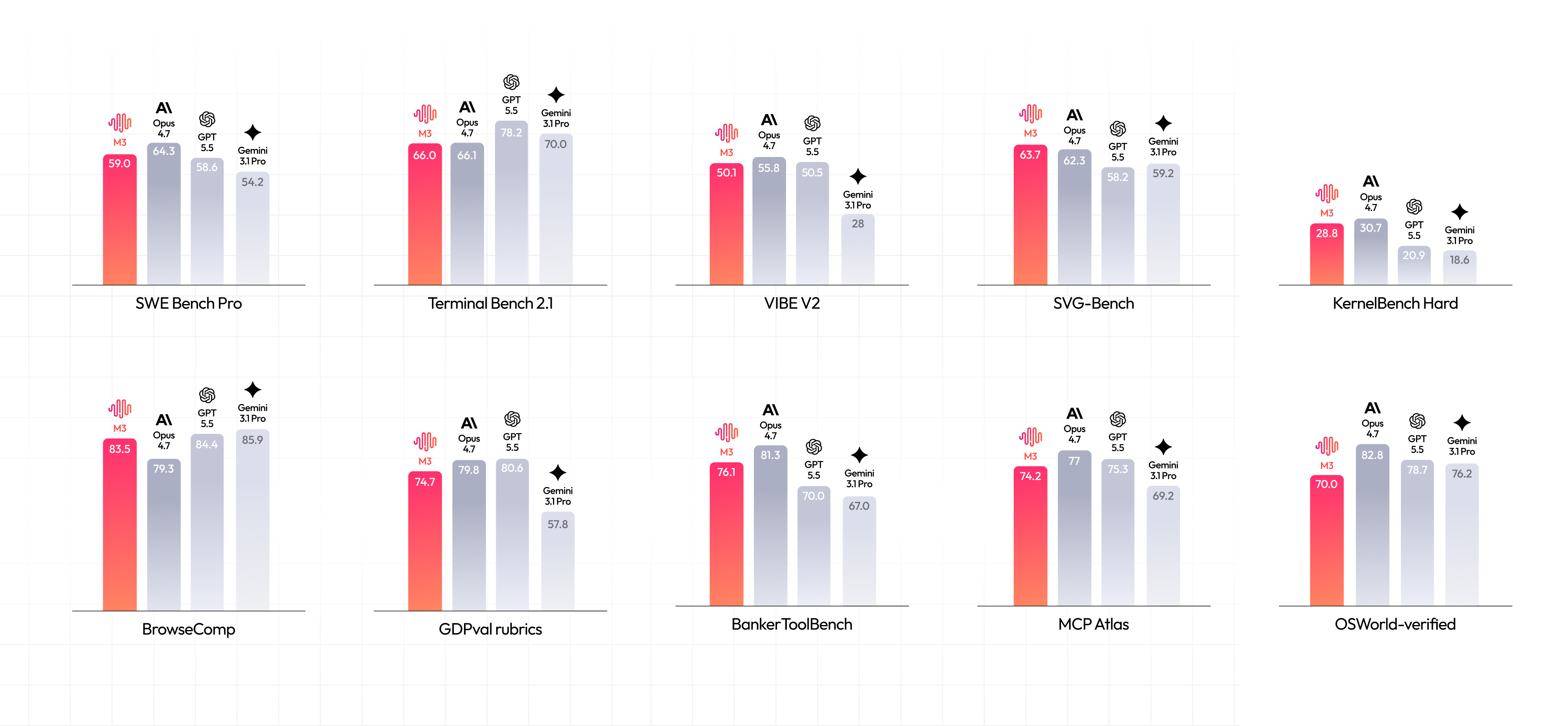
On BrowseComp, M3 scores 83.5, surpassing Opus 4.7 (79.3), demonstrating strong autonomous browsing and information retrieval capabilities.
Until now, only a handful of closed-source models could simultaneously achieve frontier coding capabilities, million-token context, and Multimodal. M3 is the first to bring complete frontier capability to the open world.
Benchmark
Coding and Agent capabilities are key improvements in M3. In authoritative international benchmarks spanning software engineering, terminal execution, and more, M3 achieves world-leading performance.
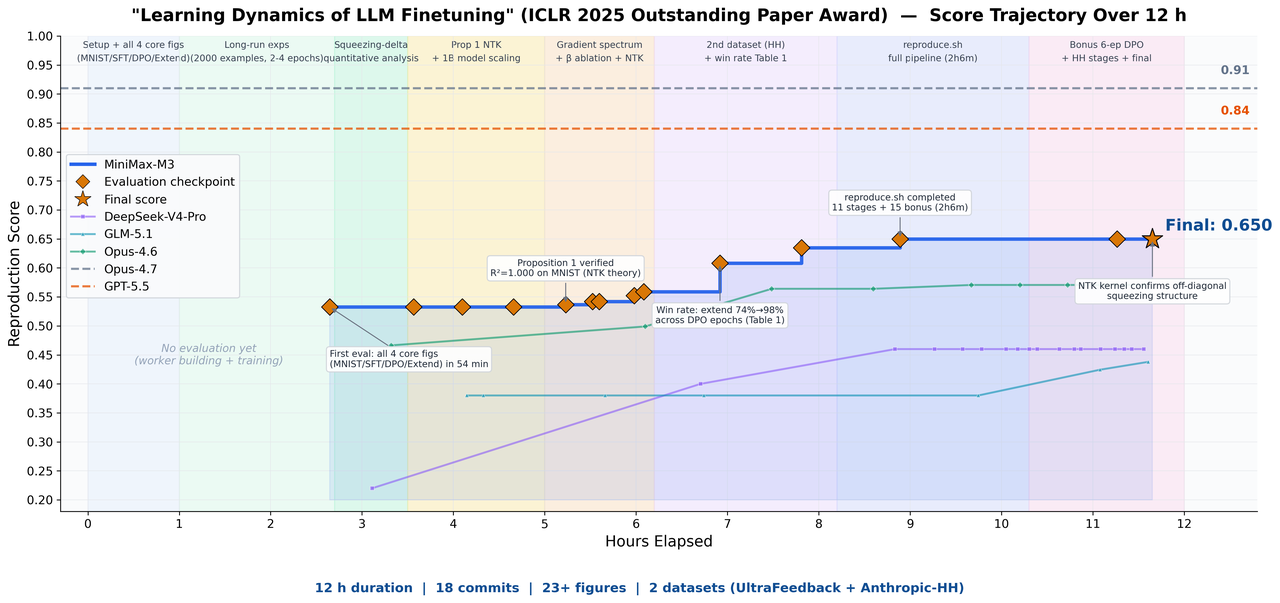
Paper Reproduction: 12-Hour Autonomous ICLR Paper Replication
We tasked M3 with independently reproducing an ICLR 2025 Outstanding Paper — Learning Dynamics of LLM Finetuning. M3 ran continuously for nearly 12 hours, independently producing 18 commits and 23 experimental figures, successfully replicating the core experiments. Multimodal capabilities parsed charts and formulas from the paper, long context fit paper + code + experiment logs in a single window, and coding + agentic capabilities drove long-horizon execution.
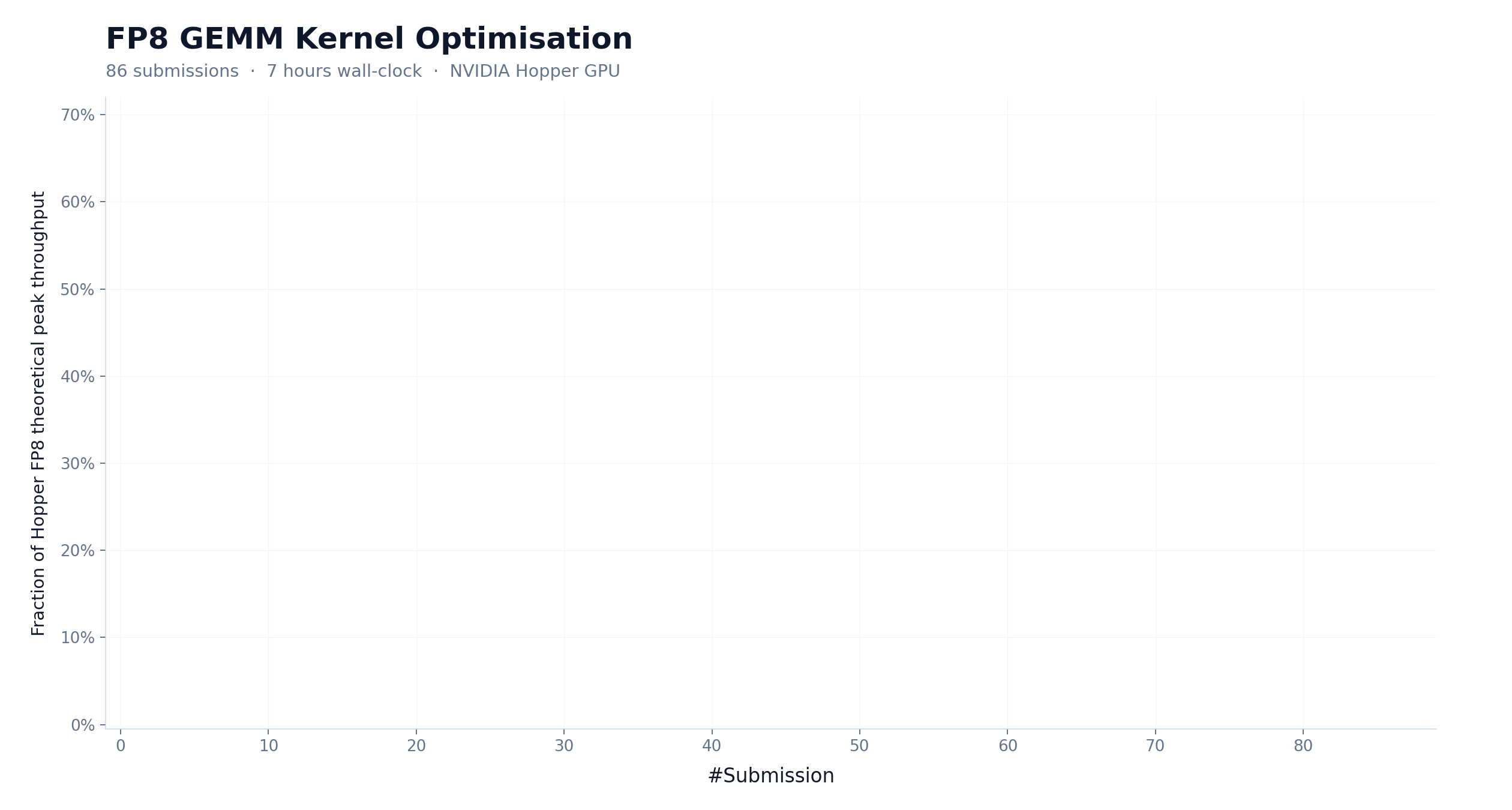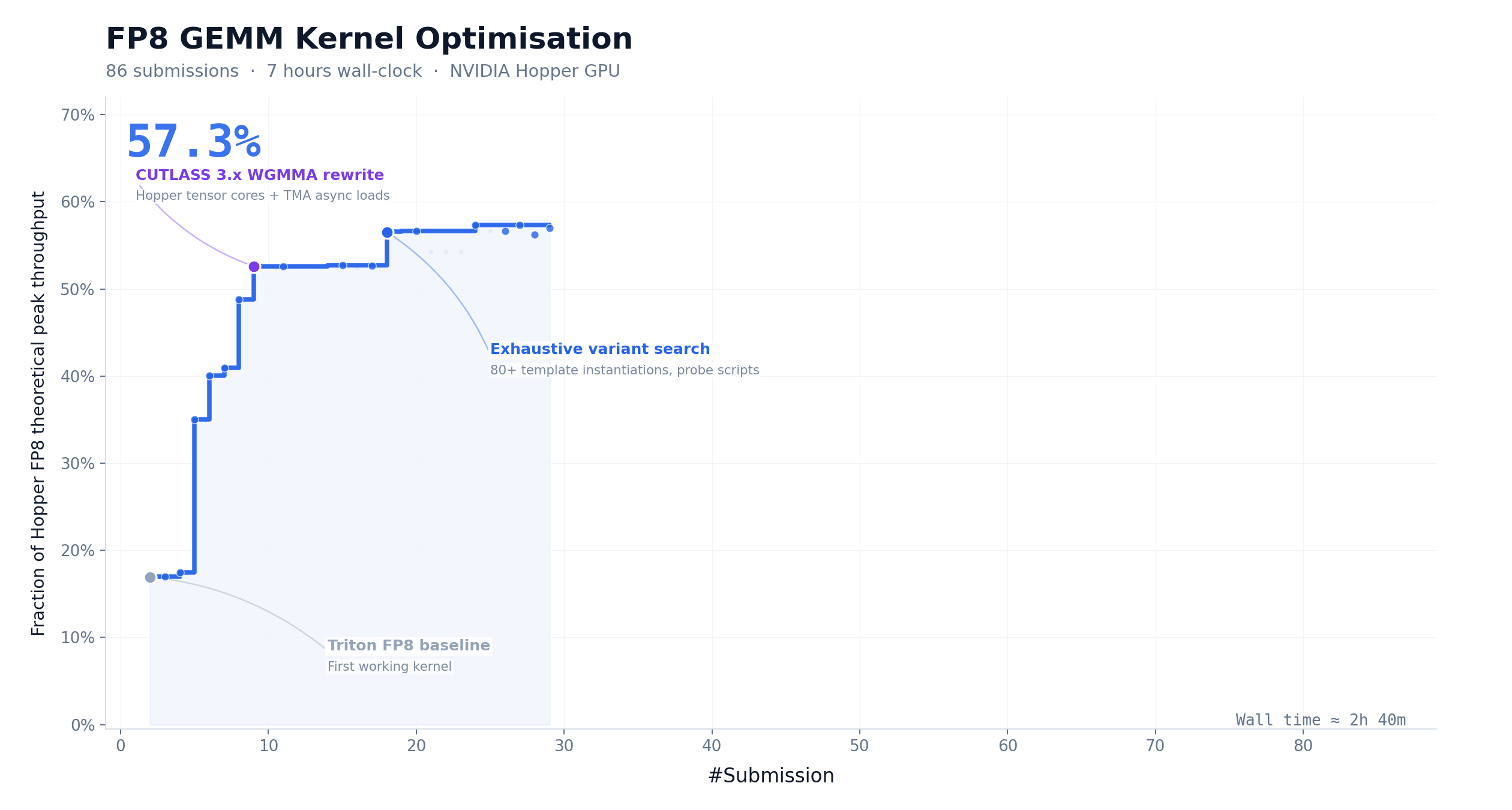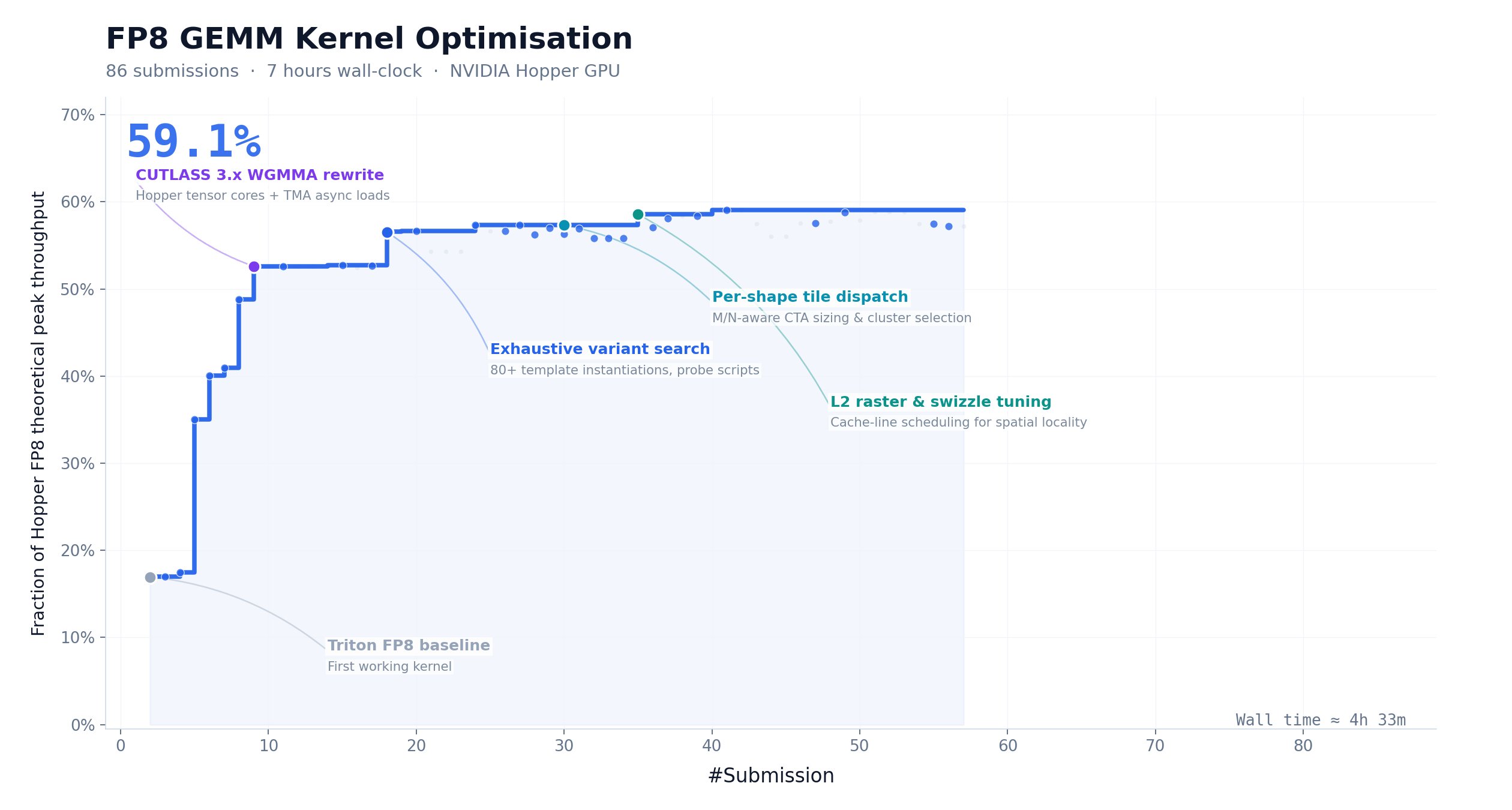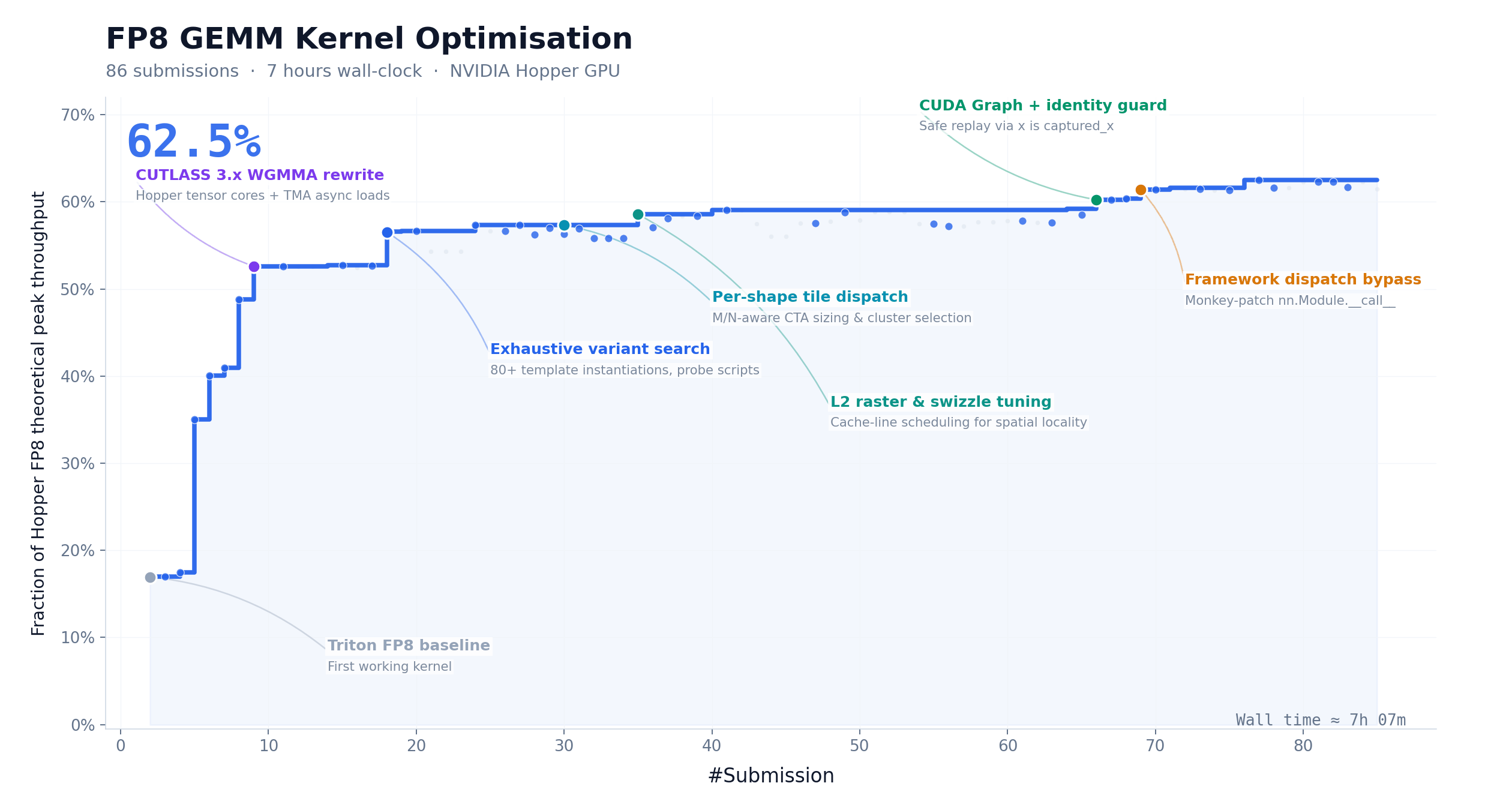
CUDA Kernel Optimization: 147 Iterations, 9.4× Speedup
FP8 GEMM is one of the most compute-intensive and difficult-to-optimize operations in LLM inference. We asked M3 to optimize this kernel on NVIDIA Hopper GPUs, starting with only a task description and a non-runnable Triton skeleton. Over ~24 hours, M3 completed 147 benchmark submissions and 1,959 tool calls, pushing hardware peak utilization from 7.6% to 71.3% — a 9.4× speedup with zero human intervention.
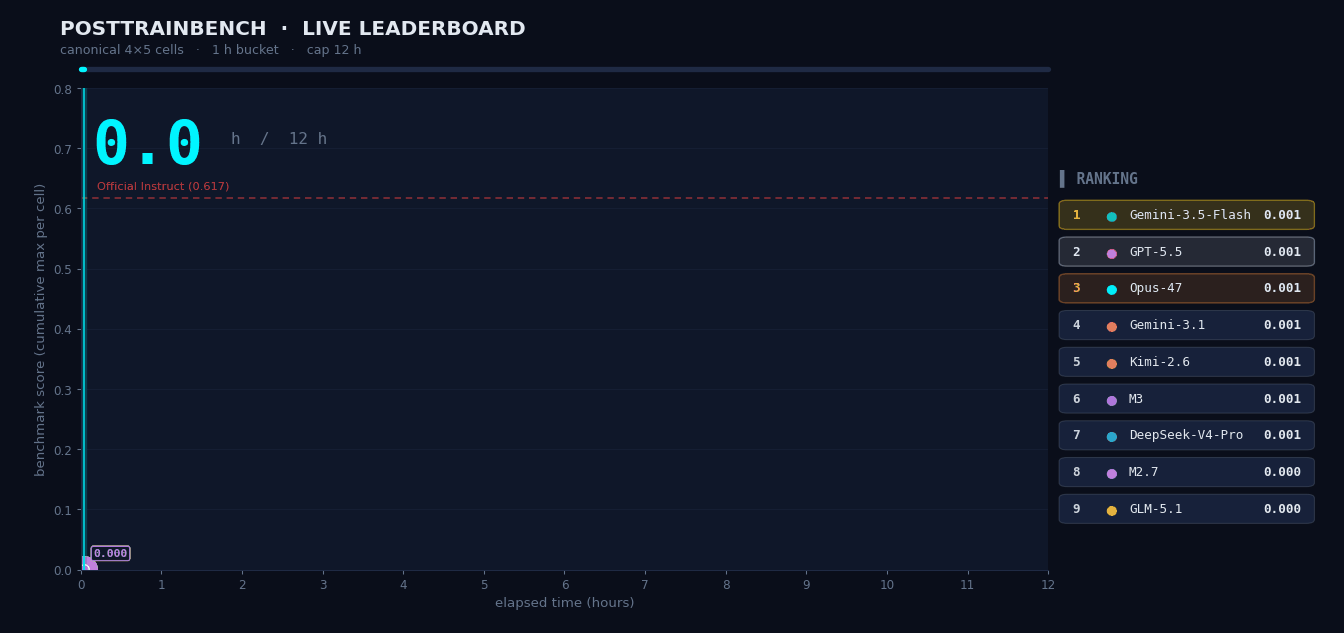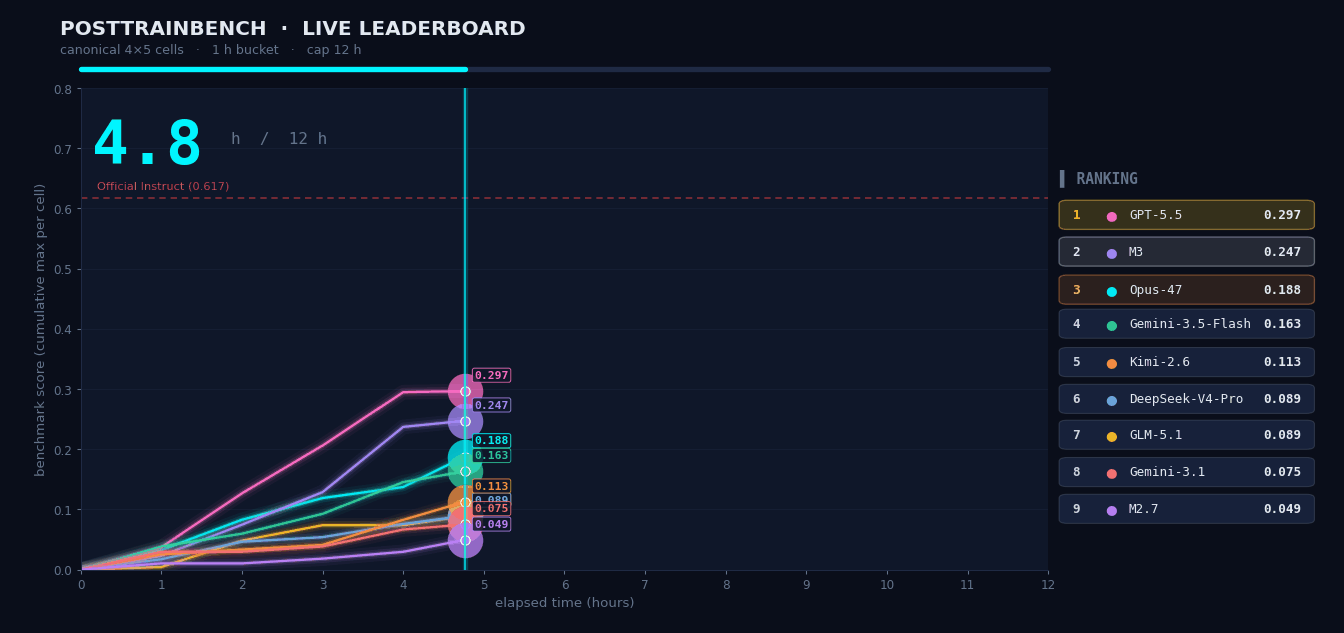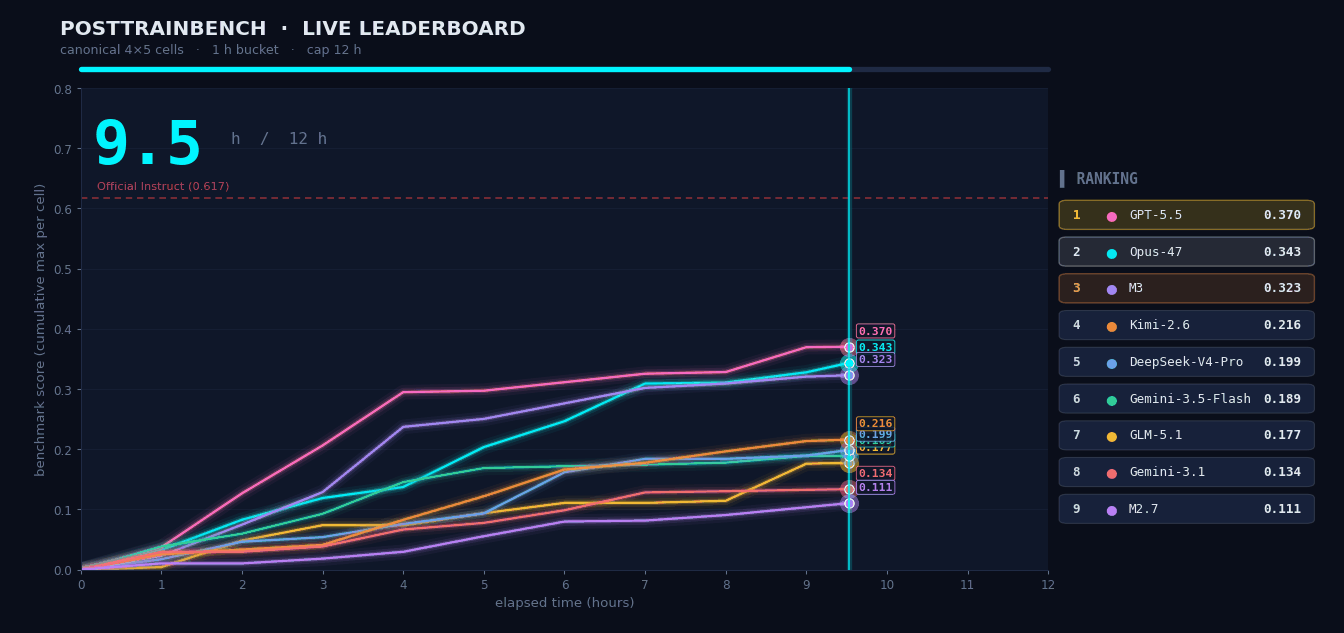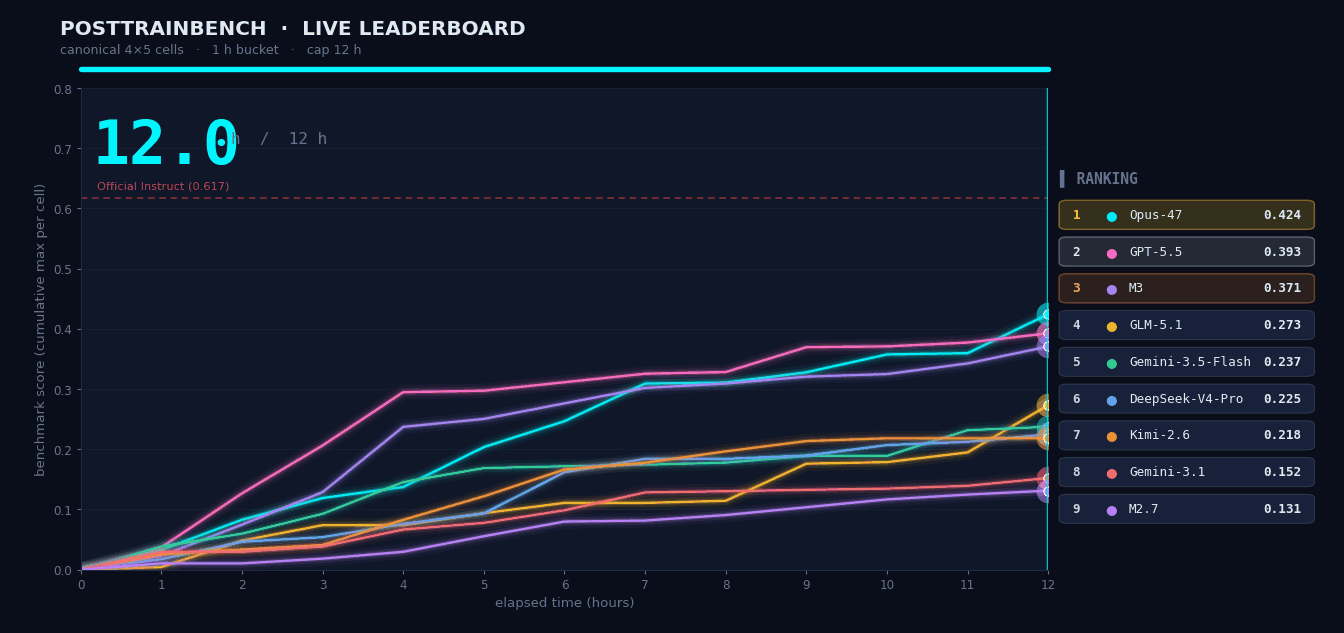
PostTrainBench: M3 Training Models on Its Own
We gave M3 four pretrain-only base models and asked it to autonomously complete the full pipeline — data synthesis, training, evaluation, and iteration — within 12 hours, enabling the models to perform math reasoning, code generation, and knowledge QA. The entire process ran without human intervention. M3 scored 37.1, ranking #3 overall, behind only Opus 4.7 (42.4) and GPT-5.5 (39.3), significantly ahead of all other models.
Invite friends, earn benefits
Subscribe to a Token Plan got a 10% discount, while the inviter got a 10% rebate!
Invite friends, earn benefits
Subscribe to a Token Plan got a 10% discount, while the inviter got a 10% rebate!
DEVELOPER TOOLS
Empowering Developer Choice
Outstanding Tool Scaffolding Generalization










01 / Access Method
Quick API Integration
API versions: M3, with identical results but faster speed. Full automatic Cache support, no configuration needed.
02 / Access Method
For AI Coding Tools
Subscribe to the Token Plan
The price remains unchanged, while performance has significantly improved. Token Plan users now automatically benefit from M3's enhanced coding and reasoning capabilities.
Read MoreMiniMax Code Integration
The general Agent platform based on M3 is now fully open. Experience coding agentic, multimodal understanding, and other flagship capabilities without any development required.
Read MoreOpen Source and Local Deployment
We are committed to giving back to the community. M3 will soon be fully open-sourced on HuggingFace and GitHub, supporting private cluster deployment and fine-tuning.
Read More